I Spent Over $200 Teaching a Model What 'Clean' Means
Over a few weekends, I built a little project to ask questions about Los Angeles restaurant health inspections using OpenAI's Platform API. The dataset isn't crazy — just over 100k records. Just to be safe, I set a $5 daily budget cap on my demo app because I figured that was generous. It's a toy project — how many queries could possibly hit my cap?
Four, that's how many. Each one packed around 106,000 inspection records into the model's context window as raw CSV. With GPT 5.4, each query cost around $1.40. The fifth query bounced, forcing me to raise my own cap just to keep working on the thing.
Meanwhile, I'd built a second approach to the same problem — a structured pipeline that never sends raw data to the model at all. Same questions, same dataset. That's where I found savings — less than a penny per query. The $5 that choked on four context-packed queries would have covered about 1,600 of these.
That gap is what this post is about. Not which approach is "better" — but what you're actually trading when you choose one over the other.
What I built and why
The question I hear constantly in analytics engineering circles — in conference talks, in the blogs I read, in the way practitioners talk about AI — is the same: when someone asks a data question and an LLM answers it, how do you know the answer is right? The models keep getting better at sounding right. The part where you can actually verify the output is still a mess.
That's both the cost question and the correctness question. Packing a context window isn't just expensive — it also means you're trusting the model to do math, interpret definitions, and decide what "good" means, all at once, with no audit trail. A harness — structured code around a model that steers it toward specific outcomes — gives you a handle on both problems.
Cocina is my attempt to explore that. The app takes 106,694 LA County restaurant health inspections — spanning two years of scores, grades, violations, and facility types across 122 neighborhoods — and lets you ask questions about them in natural language.
Try it yourself: acwx.net/apps/cocina
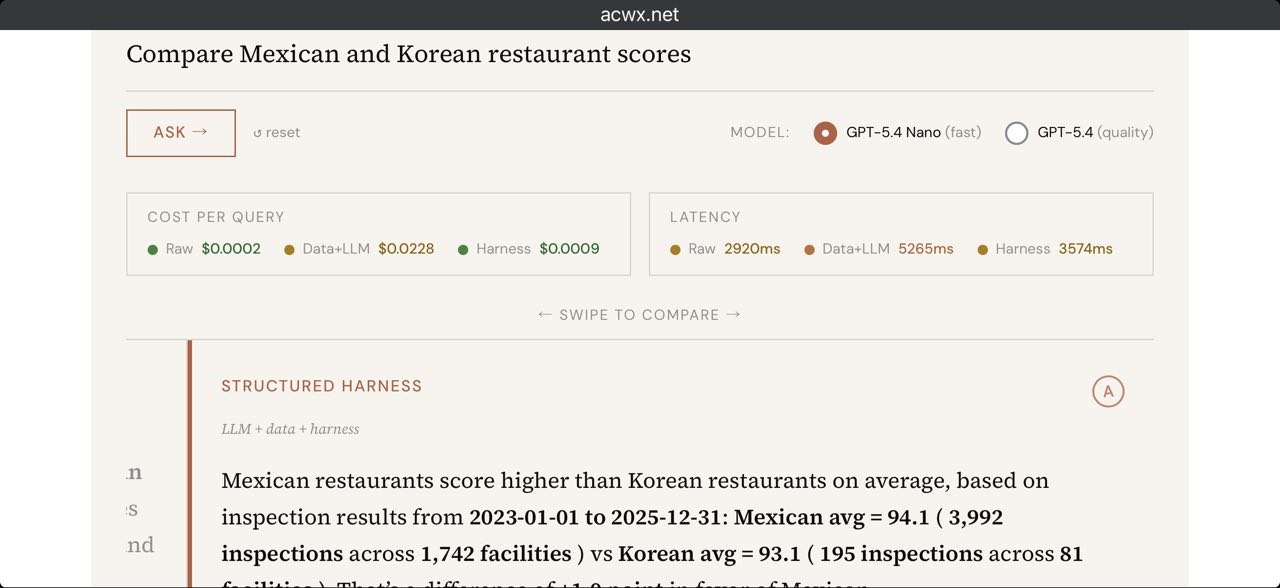
To test the idea, I ran the same question through three approaches side by side.
The raw model: I literally just ask it a question as if the model had been trained on this data. "Which neighborhood has the highest-rated restaurants?" You'll get an answer back — but it's relying entirely on what the model has already seen. No one builds production systems this way — I include it as a baseline to show what happens with zero context.
The data-stuffed model: The lazy-but-good-enough approach. Take all 106K records, download them, and mash them into the context window. From here, you're relying on the model to do its own math — computing averages, looking for outliers. The interesting thing is that with frontier models, it does pretty well, which I didn't totally expect. The catch: on GPT 5.4, it costs about $1.40 per query. Depending on how many questions you ask, that eats up cost fast. You'll soon read about how testing this approach led to a $216 bill from OpenAI.
The harnessed model: Steer the model with software. Rather than ask a raw question and hope for the best, or stuff all the records into the context window, here you write software to compute and do a lot of the work ahead of time — then only use the model to figure out what code to run and narrate the result back. Because most of the logic lives in actual software, you're not packing the context window, so queries are cheap whether you're using a frontier model or a distilled one. And because you're returning software-computed values instead of leaving it to the model's interpretation, you always get the same math back.
I'm not trying to crown a winner here. I want to know what you're actually giving up when you pick one of these approaches over another.
What "harness" means in practice
I like Martin Fowler's definition:
A well-built outer harness serves two goals: it increases the probability that the agent gets it right in the first place, and it provides a feedback loop that self-corrects as many issues as possible before they even reach human eyes. Ultimately it should reduce the review toil and increase the system quality, all with the added benefit of fewer wasted tokens along the way.
A harness is structured code around a model that steers it toward specific outcomes. So I set out to build one. What would it actually mean to build a harness that classifies and delivers restaurant inspection results? After some tinkering, I landed on a six-stage pipeline. Two stages involve the model. Four are just code.
The intent classifier reads your question and maps it to a structured query. "What's the average health score in Koreatown?" becomes a specific metric, dimension, and filter. This is the only part of the pipeline where the model makes a judgment call — deciding how your question maps to a specific metric.
The query planner generates an exact lookup from the predefined metric dictionary. This and the next two stages are all code — no model involved, no cost.
The metric resolver fetches pre-computed aggregates. I've already pre-aggregated all the metrics I want based on the dataset, so this step just finds the right set of results that are already calculated. This is also where the harness trades flexibility for consistency — because it only knows about pre-aggregated metrics, it can't answer questions about specific restaurants. That tradeoff comes back later.
The validator checks sample sizes and data sufficiency — is this data trustworthy enough to return?
The narrator is the second and final LLM call. It takes the structured result and puts it back in a way that's readable — context about what the numbers mean and what the data doesn't cover.
The verifier is code again — it checks the narrator's output against the raw data to catch hallucinated numbers or misstatements before the response reaches the user.
The model only touches the edges — translating a question on the way in and narrating an answer on the way out. Everything in between is just code.
Crafting a definition layer
When someone asks "how clean are Echo Park's restaurants?" — what does "clean" even mean? Average health score? Percentage of A grades? Violation rate? Repeat offender frequency? These are all legitimate answers, and they tell different stories.
I had to pick. I defined a set of metrics — health score averages, grade distributions, violation rates, facility counts — and encoded them as the system's vocabulary. When you ask a question, the classifier maps it to one of these metrics. The math is pre-computed against the full dataset. The validator checks whether there's enough data to answer confidently.
// lib/cocina/metrics.ts — The Semantic Layer
// This is the heart of the harness. Each metric encodes domain knowledge
// about what "good analytics" means for restaurant health data.
import type { MetricDefinition } from "./types.ts";
export const METRICS: Record<string, MetricDefinition> = {
health_score_avg: {
id: "health_score_avg",
name: "Average Health Score",
description: "Mean inspection score (0-100) for a group of facilities",
formula: "SUM(score) / COUNT(inspections)",
dimensions: ["cuisine_type", "neighborhood", "year", "facility_type"],
validation: { min_sample_size: 5 },
unit: "points",
interpretation: {
"90-100": "Excellent — minimal violations",
"80-89": "Good — minor issues",
"70-79": "Fair — notable concerns",
"below_70": "Poor — significant violations",
},
},
...
}Those definitions live in version-controlled, tested code — not in a system prompt that silently changes behavior when someone edits it. Any change to a metric definition is traceable, reviewable, and caught by the eval suite before it ships. This matters for analytics. And for my pocketbook, they don't cost tokens. Even better, because this is code, it's testable — each metric definition has corresponding assertions in the eval suite that verify the math against ground truth from the raw dataset.
Ultimately, this is the part I think survives even if token costs drop to zero. What counts as a clean restaurant is subjective — it's a business decision, not a model one.1 How you think about average health scores versus grade distributions versus repeat offender rates is the core question of any analytics problem. That judgment has to live somewhere, and someone has to make the call. You could put it in a system prompt, but then how do you audit it over time? Putting it in code gives you what code is good at — it's auditable, it's testable, and the rest of your team can actually weigh in on it.
The result: I can use a tiny model for the actual LLM work. The model isn't computing averages or filtering datasets — it's reading a question and narrating an answer. I could use OpenAI's GPT 5.4 nano model to get similar results, more quickly, at a fraction of the cost.
Building a harness is not for the weak (or broke)
My OpenAI dashboard for March: $216.58 💀. 55 million tokens. 2,887 API requests.
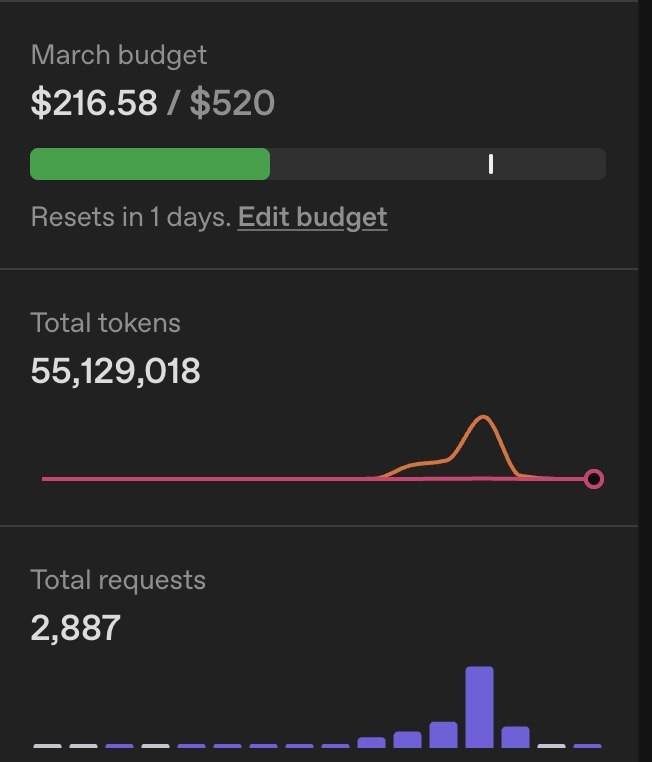
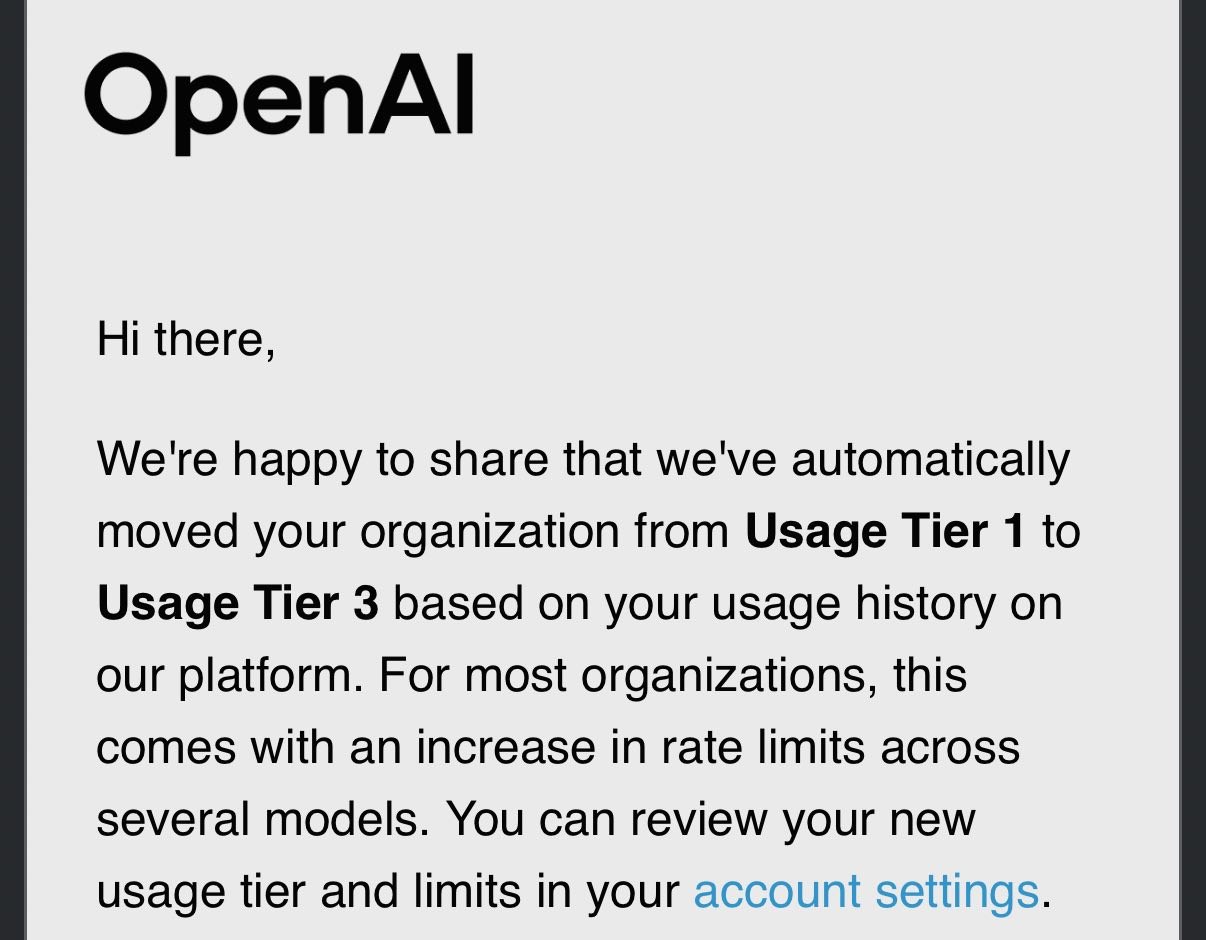
I burned through enough credits across a few weekends and roughly 20 hours of engineering time that OpenAI auto-promoted me from Tier 1 to Tier 3 — then Tier 3 to Tier 4 the following day.
Most of that was context-packed queries during development — every time I tested a question with all 106K records in context, the meter was running. The harnessed queries barely registered. I attempted to cache the requests but broke the code and had to bust/rebuild the cache several times. Every time that happened, I burned more tokens, and spent more credits.
There are no silver bullets in harness engineering
I wanted to make sure this thing actually works, so I wrote 34 targeted queries — each with ground truth computed from independent SQL aggregations against the raw CSV, locked as test fixtures before the pipeline existed — to stress the specific behaviors I care about: numerical precision, ranking accuracy, cuisine-specific questions, and edge-case handling.
These aren't meant to be exhaustive. They're smoke tests for the core use cases I built — the questions I'd be embarrassed to get wrong. If the harness can't nail these, nothing else matters.
The numbers passed: average scores, facility counts, grade distributions went 14/14. Rankings — cleanest neighborhoods, head-to-head comparisons — went 5/5. Pre-computed aggregates do the work here, which means there's no interpretation to get wrong. Cuisine-specific queries — Korean in Koreatown, Mexican in East LA, Thai in Hollywood — went 6/6. Behavioral queries (rejecting off-topic questions, deflecting recommendation requests) went 6/6. Boundary-behavior queries — the ones designed to test what happens when the data is thin or missing — went 3/3. (Slightly better than Chipotle's support bot.)
But the more interesting story was the failure I found outside the eval suite. While testing, I asked for the best Jamaican restaurant in Leimert Park — one of the few neighborhoods in LA with Caribbean food. The harnessed result said there weren't any. This was obviously wrong. Then I asked for the worst-rated restaurant in that neighborhood — and got back a Jamaican restaurant.
And right there was the limitation of my harness. This is a consequence of pre-aggregation — the harness only knows about metrics I've defined, not individual restaurant records. A harness could be designed to handle both aggregates and row-level lookups, but that's more engineering. I chose consistency over flexibility, and this is what it costs. In an actual analytics product, this would be a massive trust buster.
I thought I'd solved all these problems after dealing with the Jamaican restaurant, but then there was another one I didn't find until right before publishing this post. I asked for the best French restaurants in Culver City on a whim and got nothing back. As someone who lives in LA, I had a high suspicion there's at least one French restaurant in Culver City. Sure enough — Simonette on Washington Boulevard, Meet in Paris a few blocks away. Several well-known spots, and my system was saying they didn't exist.
This one wasn't even a harness logic problem — it was LA County's actual inspection dataset. There's no cuisine field. No column that says "this is a French restaurant." I had a light classifier, but it wasn't doing real work to figure out cuisine type. So I built a better one — a batch job that runs once, before any user touches the app, classifying all 28,000 restaurant names ahead of time. "Sushi Roku" is probably Japanese, "Tacos El Gordo" is probably Mexican. That handles the obvious names. For the rest, I brought the LLM back in to guess — but even then, Simonette didn't obviously come off as French. And Meet in Paris is sometimes abbreviated as just "Meet," which could be anything — a café, a bar, you name it. The harness now falls back to showing you everything in the neighborhood with an honest caveat about the gap — but it's still a gap.
This is the part that's easy to skip when you're building a harness. You write these really tight pipelines with structured queries and pre-computed aggregates, and still get burned by what's not in your data. The data you bring in is just as important as what you build around it. No amount of engineering fixes bad or limited data.
That's the tradeoff you're making. The data-stuffed approach, for all its cost problems, found specific low-scoring restaurants by name that the harness couldn't — because it was looking at raw records, not aggregates. When a harnessed query fails, you can trace exactly why through debuggable code — and for anyone building analytics tools where the methodology needs to be defensible, that debuggability is how you earn trust. When a context-stuffed query gives you a wrong number, figuring out why is harder. (Tools like Braintrust and LangChain help with eval and observability for the stuffed approach — but having testable code you can debug locally is a different kind of confidence.)
Should you build a harness?
For exploration — ad-hoc questions where you want the model to surprise you — stuffing the context might genuinely be the better tool. Depending on how you value engineering time, you could stomach the cost and focus your efforts on something else.
But if you need the same question answered the same way every time — and you need to show your work when someone asks why the number changed — a harness gives you that.
This is not the best harness in the world, and I'd genuinely love to hear if there's an obvious flaw in my approach. It's the one I built while learning the trade-offs. I spent a few weekends and $216 on it, and I'm still finding gaps.
The elephant in the room: models have tool use now. Any modern model can write Python code, execute it against the raw data, and give you a deterministic result. Real code, real math — not just a prediction based on tokens. That honestly solves a lot of what I built this harness to do. The math is real and the context window stays intact. That said, unless you're logging and versioning everything, it's only inspectable in the moment — right when the model's running. There's a world where I built this with tool use from the start and skipped the metric resolver entirely.
But that still doesn't solve the whole problem. You still have to deal with definitions. A model with a code interpreter can compute an average — it can run a pandas describe — but it hasn't determined what "clean" even means. The model makes that call fresh every time, and you can't write a unit test for how a model might interpret "clean." For that, you need something like a function that returns a boolean. Constraining that — telling the model which metrics exist and what they mean — that is building a harness, just a lighter one. In practice, it might look like a schema listing valid metrics and their definitions. Something a human can review and a test suite can verify.
So the interesting question isn't whether you should or shouldn't have a harness. It's how much of the pipeline the model should own versus how much lives in code. These models evolve every day — tool use improves substantially — but someone still has to decide what "clean" means in this context, or when the sample size is too small to answer confidently. That logic has to live somewhere, and ideally people actually argue about it — in a pull request, in CI, in a conversation with people who haven't read the prompt. For me, the best place to put that is code.
Footnotes
-
Technically a policy decision — and you could argue there are science-backed methodologies for measuring restaurant cleanliness specifically. But in most analytical scenarios, you're making a judgment call on a concept even when you're using data to back it. That judgment is what belongs in code. ↩